
Keeping an eye on your company’s attack surface is super important these days. It’s like constantly checking all the doors and windows of your house to make sure no one’s trying to sneak in. But with all the tech we use, from cloud stuff to all sorts of apps, that surface can get pretty big and complicated. That’s where continuous attack surface monitoring comes in. It’s not a one-and-done thing; it’s an ongoing effort to see what’s out there, what risks you have, and how to keep those risks down. We’ll look at how to set up good monitoring, spot trouble, and stay ahead of the bad guys.
Key Takeaways
- You need to know what assets you have and keep good records of what’s happening on them. This is the starting point for any real security monitoring.
- Spotting threats means looking at different areas like cloud services, user accounts, applications, and even how data might leave your company. It’s a broad effort.
- Attackers are always finding new ways to get in, like messing with cloud settings, abusing APIs, or using smart tech to trick people. Staying aware of these methods is key.
- A strong defense uses many layers of security, not just one. This includes managing who has access and making sure the software you use is built securely from the start.
- Keeping track of your security with metrics helps you see what’s working and what’s not, so you can make things better over time and respond faster when something goes wrong.
Establishing Foundational Security Monitoring
Setting up a solid security monitoring system is the first step in actually seeing what’s happening on your network and systems. Without it, you’re basically flying blind, hoping for the best. This isn’t about fancy gadgets; it’s about getting the basics right so you can spot trouble before it becomes a major problem.
Asset Visibility and Log Management
You can’t protect what you don’t know you have. That’s where asset visibility comes in. It means having a clear picture of all the devices, software, and cloud services connected to your environment. Once you know what’s there, you need to collect logs from everything. Logs are like the security camera footage of your digital world, recording who did what, when, and where. Proper log management means storing these logs securely, making sure they aren’t tampered with, and keeping them for a useful amount of time. This collected data is the raw material for detecting suspicious activity.
- Know your inventory: Keep a running list of all hardware and software.
- Centralize logs: Gather event data from endpoints, servers, and network devices.
- Ensure time sync: Make sure all systems have synchronized clocks for accurate event sequencing.
Without consistent telemetry and context, detection effectiveness is severely limited. It’s like trying to solve a crime with only half the witness statements.
Centralized Event Correlation with SIEM
Collecting logs is one thing, but making sense of them is another. That’s where a Security Information and Event Management (SIEM) system comes into play. A SIEM pulls together all those disparate logs and security alerts from different sources. It then uses correlation rules to connect the dots, looking for patterns that might indicate a real threat. Instead of sifting through thousands of individual log entries, a SIEM can flag a sequence of events that, on their own, might look harmless but together suggest an attack. This helps cut down on the noise and focus on what matters. SIEM platforms collect and analyze security data to detect and respond to threats.
Endpoint and Network Traffic Analysis
Your endpoints – like laptops, servers, and mobile devices – are often the first place attackers try to get in. Endpoint Detection and Response (EDR) tools monitor these devices for unusual behavior, like processes trying to access sensitive files or making strange network connections. On the network side, analyzing traffic patterns can reveal unauthorized communication or attempts to move laterally within your network. This is especially important because attackers often try to hide in the ‘east-west’ traffic between internal systems, which traditional perimeter defenses might miss. Modern infrastructure has increased this internal traffic, creating visibility gaps.
- Monitor endpoint processes and file access.
- Analyze network flows for anomalies.
- Look for signs of malware or unauthorized access attempts.
Detecting Threats Across Diverse Environments

Cloud-Native and Identity-Based Detection
Modern IT environments are complex, spanning on-premises infrastructure, multiple cloud providers, and a growing number of SaaS applications. This diversity means threats can emerge from unexpected places. Detecting these threats requires looking beyond traditional network perimeters. Cloud environments generate a lot of data about how services are configured and used. Monitoring this data helps spot issues like unauthorized access or changes that could open the door for attackers. Similarly, identity is now a key battleground. With so many systems relying on user accounts, tracking login attempts, privilege changes, and access patterns is vital. Anomalous identity behavior, like impossible travel scenarios or repeated failed logins, can be early indicators of compromise.
- Cloud Activity Monitoring: Focuses on configuration changes, API usage, and workload behavior.
- Identity Monitoring: Tracks authentication, session activity, and privilege escalation.
- Log Analysis: Cloud-native logs provide insight into account compromise and service abuse.
Application, API, and Email Threat Detection
Applications and the APIs that connect them are prime targets. Attackers look for ways to exploit software flaws, abuse functionality, or overload services. Monitoring application performance for unusual errors or transaction patterns can reveal attacks. APIs, in particular, need careful watching for unauthorized access or excessive requests. Email remains a major entry point for threats like phishing and malware. Detecting these requires analyzing email content, sender reputation, and user-reported suspicious messages. It’s about understanding the flow of information and looking for deviations.
Data Loss and Anomaly-Based Detection
Protecting sensitive data is paramount. Data loss detection aims to identify when information is accessed, transferred, or exposed without authorization. This involves looking for unusual data movement patterns or policy violations. Often, attackers try to blend in with normal activity. This is where anomaly-based detection becomes important. Instead of looking for known bad signatures, it establishes a baseline of normal behavior and flags anything that deviates significantly. This approach is particularly useful for spotting novel threats or insider actions that might otherwise go unnoticed. However, it requires careful tuning to avoid too many false alarms. For instance, monitoring unusual file access patterns or large data transfers outside of normal business hours can signal potential data exfiltration.
Detecting threats in today’s distributed environments means looking at many different signals. It’s not just about network traffic anymore. We need to watch user actions, cloud configurations, application behavior, and how data is moving. Combining these different views gives a much clearer picture of what’s happening and helps catch threats that might otherwise slip through.
Understanding Modern Attack Vectors
Attackers are always finding new ways to get into systems, and it feels like they’re getting smarter all the time. It’s not just about finding a weak password anymore; the methods are way more sophisticated now. We’re seeing a lot of focus on exploiting cloud setups that aren’t quite right, and also this whole ‘shadow IT’ thing where people use apps and services without the IT department even knowing. It’s like leaving a back door open without realizing it.
Exploiting Cloud Misconfigurations and Shadow IT
Cloud environments, while powerful, can be tricky. Misconfigurations are a huge problem. Think about leaving a storage bucket open to the public or not setting up proper access controls on a database. These aren’t necessarily bugs in the software, but mistakes in how it’s set up. Then there’s shadow IT. Employees, trying to be productive, might sign up for a new project management tool or a file-sharing service without going through the official channels. While they might think they’re just getting work done faster, they’re often introducing unvetted applications into the company’s digital space. These apps might not have the same security standards as approved tools, creating blind spots and potential entry points for attackers. It’s a constant battle to keep track of everything that’s out there.
API Abuse and IoT Device Vulnerabilities
APIs, or Application Programming Interfaces, are the glue that holds a lot of modern applications together, especially in web services and mobile apps. They allow different software systems to talk to each other. But if an API isn’t secured properly, it can be a goldmine for attackers. They might try to abuse API functions to steal data, disrupt services, or gain unauthorized access. It’s like finding a secret tunnel into a building. On the other hand, we have the Internet of Things (IoT) devices. These are everywhere now – smart thermostats, security cameras, industrial sensors. Many of them are built with minimal security in mind, often using default passwords or having unpatchable firmware. An attacker can compromise a single vulnerable IoT device and use it as a stepping stone into a larger network.
AI-Driven Attacks and Social Engineering
Artificial intelligence is changing the game for attackers, too. They’re using AI to automate tasks that used to take a lot of manual effort. This includes things like scanning for vulnerabilities at a much faster pace or creating incredibly convincing phishing emails that are tailored to specific individuals. AI can also be used to generate deepfakes, which are fake videos or audio recordings that can be used to impersonate someone, like a CEO, to trick employees into transferring money or revealing sensitive information. This ties into social engineering, which has always been effective because it plays on human psychology. Attackers exploit trust, urgency, or curiosity to get people to make mistakes. With AI making these attacks more personalized and scalable, it’s becoming harder than ever to spot them.
Here’s a quick look at how some of these vectors are used:
| Attack Vector Category | Common Techniques |
|---|---|
| Cloud Exploitation | Misconfigured storage, weak access controls, insecure APIs |
| Shadow IT | Unvetted SaaS applications, unauthorized cloud services |
| API Abuse | Data scraping, unauthorized access, denial of service |
| IoT Vulnerabilities | Default credentials, unpatched firmware, insecure network protocols |
| AI-Driven Attacks | Automated reconnaissance, personalized phishing, deepfakes |
| Social Engineering | Phishing, spear-phishing, pretexting, baiting |
Understanding these modern attack vectors is key. It’s not enough to just put up firewalls anymore. We need to think about how attackers are using technology and human behavior together to find weaknesses. This means looking at everything from how cloud services are set up to how people interact with emails and devices.
Implementing Layered Defense Strategies
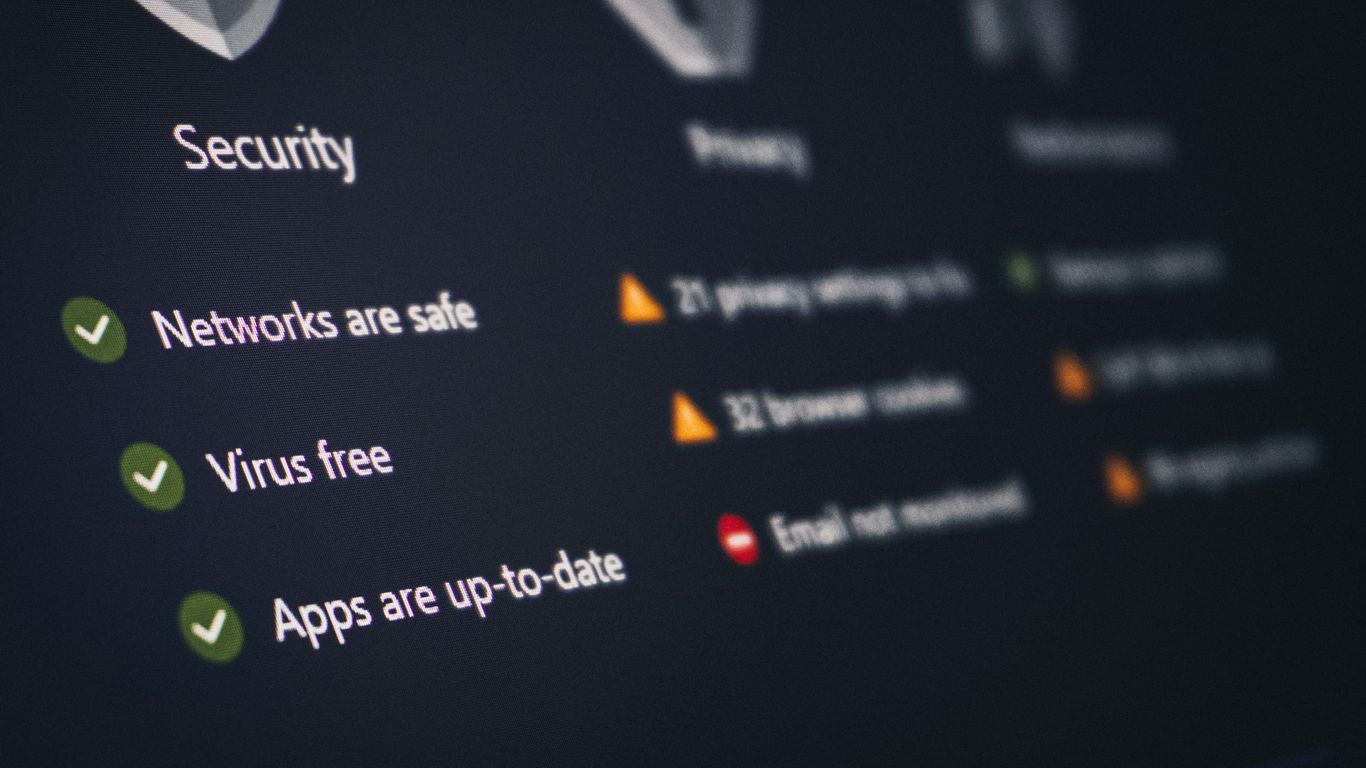
Building a strong security posture isn’t about a single magic bullet; it’s about creating multiple barriers that make it harder for attackers to get in and move around. This approach, often called defense in depth, means we don’t rely on just one tool or technique. If one layer fails, others are there to catch the threat. Think of it like a castle with a moat, high walls, and guards – each element adds to the overall security.
Defense in Depth and Network Segmentation
Defense in depth is all about stacking controls. We’re talking about putting security measures at every level, from the network edge all the way down to individual applications and data. This layered approach means that even if an attacker bypasses the firewall, they still have to get through intrusion detection systems, endpoint protection, and access controls. It’s a lot more work for them, and a lot more security for us. Network segmentation takes this a step further. Instead of one big, flat network where a breach in one spot can spread everywhere, we break the network into smaller, isolated zones. This limits an attacker’s ability to move laterally, or "east-west," across systems. If one segment is compromised, the damage is contained to that area, preventing a domino effect. This is a key part of building an Enterprise Security Architecture.
Identity-Centric Security and Access Governance
In today’s world, the old idea of a trusted internal network versus an untrusted external one doesn’t really hold up anymore. With cloud services and remote work, the perimeter has dissolved. That’s why we’re shifting towards an identity-centric model. This means we verify who is trying to access something, and what they’re allowed to do, regardless of where they are. Strong authentication, like multi-factor authentication (MFA), is non-negotiable. Access governance then comes into play, making sure users only have the permissions they absolutely need to do their jobs – no more, no less. This principle of least privilege is vital. Regularly reviewing who has access to what and removing unnecessary permissions helps close down potential entry points.
Secure Development and Cryptographic Controls
Security can’t just be an afterthought; it needs to be built into applications from the very beginning. This means integrating security practices into the software development lifecycle. Things like threat modeling, secure coding standards, and regular vulnerability testing during development catch issues early, when they’re cheapest and easiest to fix. On the data protection side, cryptography is our friend. Encryption scrambles sensitive data, making it unreadable to anyone without the right key, whether it’s data stored on a disk (at rest) or data moving across the internet (in transit). Proper key management is just as important as the encryption itself; losing keys means losing access to your data, or worse, having it fall into the wrong hands. These combined strategies create a robust defense that addresses both system vulnerabilities and data confidentiality.
Building layered defenses is about creating a security ecosystem where different controls work together. It’s not just about technology; it’s also about processes and people. When these elements are aligned, they significantly reduce the overall risk to the organization.
Leveraging Threat Intelligence for Proactive Defense
Knowing what’s coming is half the battle, right? That’s where threat intelligence comes in. It’s not just about reacting to attacks; it’s about getting ahead of them. Think of it as having a heads-up on what bad actors are up to, what tools they’re using, and where they might strike next. This kind of information helps us build better defenses before we even see the attack.
Integrating Threat Intelligence Feeds
So, how do we actually use this intelligence? We bring it into our security systems. This means connecting to feeds that provide lists of known bad IP addresses, malicious domains, or specific malware signatures. These indicators of compromise (IOCs) can then be used by our firewalls, intrusion detection systems, and SIEMs to block or flag suspicious activity. It’s like giving your security guards a watchlist of known troublemakers. The key is making sure the intelligence is relevant and timely.
Here’s a look at how different systems can use threat intel:
| System Type | How Threat Intel is Used |
|---|---|
| SIEM | Correlates events with known IOCs, identifies suspicious patterns. |
| Firewall | Blocks traffic to/from known malicious IPs and domains. |
| Endpoint Detection and Response (EDR) | Detects known malware signatures and suspicious file behaviors. |
| Email Gateway | Filters out phishing attempts and malicious attachments based on intelligence. |
Signature-Based vs. Anomaly-Based Detection
When we talk about detection, there are two main flavors: signature-based and anomaly-based. Signature-based detection is like having a fingerprint database for known threats. If something matches a known signature, it’s flagged. It’s great for catching common, well-understood attacks. However, it struggles with new or modified threats. That’s where anomaly-based detection comes in. This approach looks for deviations from normal behavior. It establishes a baseline of what’s typical for your environment and then alerts you when something unusual happens. This can catch novel attacks that signature-based systems would miss. The challenge here is that ‘unusual’ can sometimes just be a new, legitimate process, leading to false positives. Finding the right balance is important.
The effectiveness of any detection method hinges on the quality and context of the data it analyzes. Without good telemetry, even the most sophisticated algorithms will struggle to distinguish friend from foe. This is why robust log management and endpoint telemetry correlation systems are so vital.
Understanding Threat Actor Models and Motivations
Why do attackers do what they do? Understanding their motivations helps us predict their actions. Are they after financial gain, looking to steal sensitive data for espionage, or just trying to cause disruption? Different motivations lead to different tactics. For instance, a financially motivated attacker might focus on ransomware or business email compromise schemes, while a state-sponsored actor might be more interested in long-term espionage and stealthy data exfiltration. Knowing these models, like the intrusion lifecycle, helps us align our defenses to counter specific types of threats. It’s about thinking like the adversary to build a stronger defense against sophisticated cyber threats. Understanding these techniques is key to staying ahead.
Managing Vulnerabilities and Attack Surface
Keeping your digital doors locked and windows shut is a constant job, right? That’s pretty much what managing vulnerabilities and your attack surface is all about. It’s not a one-and-done task; it’s more like keeping up with home maintenance, but for your company’s digital presence. You’ve got to know what you have, where it’s exposed, and then actively work to fix those weak spots before someone decides to take advantage.
Continuous Vulnerability Management
Think of vulnerability management as a regular check-up for your systems. You’re constantly looking for weaknesses, like unpatched software or misconfigured settings, that attackers could use. It’s a process that involves finding these issues, figuring out how bad they are, and then fixing them. The goal is to reduce the chances of a breach by closing those gaps before they become a problem. It’s really about staying ahead of the game.
Here’s a look at the typical steps:
- Discovery: Regularly scan your systems and applications to find any known vulnerabilities.
- Assessment: Evaluate the severity of each vulnerability, considering factors like how easy it is to exploit and the potential impact.
- Prioritization: Decide which vulnerabilities need fixing first, usually based on risk.
- Remediation: Apply patches, update software, or change configurations to fix the identified issues.
- Verification: Confirm that the fixes have been applied correctly and the vulnerability is no longer present.
The most common attacks often exploit well-known flaws. If you’re not actively managing and fixing these, you’re essentially leaving the front door wide open for common threats.
Reducing Attack Surface Through Visibility
What exactly is your attack surface? It’s everything that’s exposed to the outside world – your servers, applications, user accounts, even third-party services you use. The bigger this surface is, the more opportunities there are for an attacker to find a way in. So, the key here is visibility. You can’t protect what you don’t know you have. This means keeping a sharp eye on all your assets, understanding how they connect, and identifying any unnecessary exposure. For instance, having old, unneeded servers running can significantly increase your attack surface without adding any real business value. It’s about trimming the fat, so to speak.
Here are some common areas that expand your attack surface:
- Exposed Services: Applications or ports that are open to the internet but not strictly necessary.
- Shadow IT: Unsanctioned applications or devices used by employees that IT isn’t aware of or managing.
- Weak Credentials: Reused passwords or accounts without multi-factor authentication.
- Unpatched Software: Systems running outdated software with known security holes.
Risk Management and Mitigation Strategies
Once you know what your vulnerabilities are and what makes up your attack surface, you need a plan. Risk management is about figuring out which of these issues pose the biggest threat to your organization and then deciding what to do about them. Not all risks can be eliminated entirely, so you often have to choose the best way to handle them. This could mean fixing the problem directly, transferring the risk (like with cyber insurance), or sometimes, accepting a certain level of risk if the cost of mitigation is too high compared to the potential impact.
Common mitigation strategies include:
- Patch Management: Regularly applying updates to software and systems. This is one of the most effective ways to close known security gaps. Timely patching is key.
- Configuration Management: Setting up systems with secure defaults and monitoring for any changes that could weaken security.
- Access Controls: Implementing strict rules about who can access what, following the principle of least privilege.
- Network Segmentation: Dividing your network into smaller, isolated zones to limit how far an attacker can move if they get in.
It’s a continuous cycle: find weaknesses, assess risks, implement controls, and then start the process over again. Keeping your digital footprint clean and secure is an ongoing effort.
Enhancing Detection Effectiveness with Metrics
So, how do we know if our security detection is actually working? It’s not enough to just have tools in place; we need to measure their performance. This is where metrics come in. They give us a way to see what’s good, what’s bad, and where we need to focus our efforts.
Measuring Mean Time to Detect and Alert Volume
One of the most talked-about metrics is Mean Time to Detect (MTTD). Basically, it’s the average time it takes from when something bad actually happens to when our systems flag it. The lower this number, the better, because it means we’re catching threats faster, giving us a better chance to stop them before they do too much damage. Think of it like a smoke alarm – the sooner it goes off, the sooner you can deal with the fire.
Another metric to watch is alert volume. Are we getting flooded with alerts? If so, it might mean our systems are too sensitive, or we’re just seeing a lot of noise. On the flip side, if we’re getting very few alerts, it doesn’t automatically mean things are quiet; it could mean our detection isn’t sensitive enough. We need a balance here.
Assessing Coverage Completeness and False Positives
Coverage completeness is about asking: are we monitoring everything we should be? This means looking at our assets, our networks, our cloud environments, and our applications. Are there blind spots where an attacker could sneak in unnoticed? We need to make sure our detection tools have a good view of the whole landscape. For example, understanding network traffic baselines is key to knowing what’s normal and what’s not Establishing a network traffic baseline.
Then there are false positives. These are alerts that look like a threat but turn out to be harmless. Too many false positives can lead to alert fatigue, where security teams get so used to seeing them that they might miss a real threat. We need to tune our systems to reduce these as much as possible, without sacrificing the ability to catch actual malicious activity. It’s a constant balancing act.
Using Metrics to Guide Tuning and Improvement
These metrics aren’t just numbers to look at; they’re guides. If our MTTD is too high, we need to investigate why. Is it our tools? Our processes? Our team’s response time? If alert volume is overwhelming, we need to adjust our detection rules. If coverage is incomplete, we need to deploy more sensors or expand our monitoring scope. For instance, fileless attacks can be tricky to spot, and understanding how they work helps us tune our endpoint detection Detecting fileless intrusion persistence.
Metrics help us move from guessing to knowing. They provide objective data to justify investments in security tools, training, and process improvements. Without them, we’re essentially flying blind, hoping our defenses are adequate.
Here’s a quick look at how metrics can inform action:
- High MTTD: Investigate detection delays, review alert triage processes, and consider faster tools.
- High Alert Volume: Tune detection rules, implement better alert prioritization, and automate initial analysis.
- Low Coverage: Identify asset gaps, deploy new monitoring solutions, and review cloud configurations.
- High False Positive Rate: Refine detection signatures, adjust anomaly thresholds, and provide more context to alerts.
Automating Detection and Response Processes
Trying to keep up with every single alert and potential threat manually is a losing game. That’s where automation comes in. It’s not about replacing human analysts entirely, but about giving them superpowers to handle the sheer volume and speed of modern cyber threats. Think of it as having a tireless assistant that can sift through mountains of data, spot the really bad stuff, and even start taking action before you even finish your coffee.
Scalability and Consistency Through Automation
When you’re dealing with a complex environment, from cloud services to on-prem servers, manual monitoring just doesn’t scale. Automation helps here by providing consistent checks and balances across all your systems. It means that a suspicious login attempt on a cloud server gets the same level of scrutiny as one on a local workstation, every single time. This consistency is key to not missing things.
- Automated Log Analysis: Tools can automatically collect, normalize, and analyze logs from diverse sources, looking for patterns that indicate trouble. This is way faster than a person trying to read through thousands of log entries.
- Playbook Execution: For common incident types, automated playbooks can be set up. These are pre-defined sequences of actions, like isolating an infected machine or blocking a malicious IP address. This speeds up the initial containment phase significantly.
- Asset Discovery and Inventory: Automation can continuously scan your network and cloud environments to keep an up-to-date inventory of all assets. Knowing what you have is the first step to protecting it, and manual inventory management is a chore nobody enjoys.
Automation helps bridge the gap between the speed of attacks and the capacity of human teams. It allows security operations centers (SOCs) to focus on complex investigations and strategic improvements rather than getting bogged down in repetitive tasks.
Adapting to Environmental and Threat Changes
Environments change, and so do the ways attackers try to get in. Automation needs to be flexible enough to keep up. This means systems that can learn from new data, update their detection rules, and adapt their response actions as needed. For instance, if a new type of malware starts making the rounds, automated systems can be updated with new indicators of compromise (IOCs) to spot it quickly. This is where integrating threat intelligence feeds becomes really important, feeding new data into your automated systems so they can adapt. It’s also about using techniques like living off the land detection, where automated tools look for unusual uses of legitimate system processes, which is a common tactic for attackers trying to hide.
Streamlining Incident Identification and Containment
Getting to the bottom of an incident quickly is critical. Automation can speed up both identification and containment. When an alert fires, automated systems can gather context, enrich the data with threat intelligence, and even perform initial triage. This helps analysts quickly understand the severity and scope of an issue. For containment, automated actions can be triggered based on the type and severity of the incident. This might involve:
- Isolating Endpoints: Automatically disconnecting a compromised laptop from the network.
- Blocking Malicious IPs: Updating firewalls or network access control lists to block known bad actors.
- Disabling User Accounts: Temporarily suspending accounts showing signs of compromise.
This rapid response minimizes the attacker’s ability to move laterally or cause further damage. It’s about getting ahead of the problem before it gets out of hand, which is especially important when dealing with threats like AI-driven attacks that can operate at machine speed.
Strengthening Incident Response Capabilities
When an incident happens, and it will, having a solid plan for how to deal with it is super important. It’s not just about putting out fires; it’s about doing it fast and smart to keep things from getting worse. This means having clear steps for what to do when something goes wrong, who’s in charge, and how everyone talks to each other. Without this, you’re just scrambling in the dark, and that’s when real damage happens.
Foundations of Incident Response Planning
Getting your incident response plan together starts with the basics. You need to know who does what. This involves defining roles, like who’s the main point person, who handles technical stuff, and who talks to management or legal. Setting up clear escalation paths is also key – knowing when to bring in more senior people or external help. Communication protocols are another big piece; how will the team talk to each other, and how will updates be shared? Having these things written down and practiced means less confusion and faster action when a real event occurs. It’s about building a predictable process for an unpredictable situation.
- Defined Roles and Responsibilities: Clearly assign who is responsible for each aspect of the response.
- Escalation Procedures: Establish when and how to escalate an incident to higher levels of authority or specialized teams.
- Communication Channels: Set up reliable methods for internal team communication and external stakeholder updates.
- Decision Authority: Designate who has the authority to make critical decisions during an incident.
Eradication Activities and Root Cause Analysis
Once you’ve contained an incident, the next big step is getting rid of whatever caused it and figuring out why it happened in the first place. Eradication isn’t just about deleting malware; it’s about making sure the attacker can’t get back in. This might mean patching a vulnerability, fixing a misconfiguration, or revoking compromised credentials. If you don’t get rid of the root cause, you’re just setting yourself up for another incident down the road. That’s where root cause analysis comes in. It’s like being a detective, digging into the logs and system data to understand the full story – how they got in, what they did, and what allowed it to happen. This analysis is vital for preventing future attacks and improving your overall security posture. It’s about learning from mistakes, not just fixing them.
Understanding the root cause is more than just a technical exercise; it’s a critical step in preventing recurrence and building a more resilient security program. Without this deep dive, organizations risk repeating the same mistakes.
Cybersecurity Response and Recovery Overview
After the dust settles from an incident, the work isn’t over. Cybersecurity response and recovery are about getting back to normal and making sure you’re stronger afterward. Recovery means restoring systems and data, often from backups, and making sure everything is working as it should. But it’s also about looking back at what happened. This is where post-incident reviews come in. You analyze the incident, see what went well in your response, what didn’t, and what lessons can be learned. This feedback loop is what makes your incident response better over time. It’s about turning a bad event into an opportunity to improve your defenses and your ability to handle future threats. This continuous improvement is key to staying ahead in the cybersecurity game. For organizations looking to understand how attackers operate, studying intrusion lifecycle models can provide valuable context for response planning.
| Phase | Key Activities |
|---|---|
| Detection | Identifying suspicious activity, validating alerts, assessing severity. |
| Containment | Limiting the spread of the incident, isolating affected systems. |
| Eradication | Removing the threat and its root cause, patching vulnerabilities. |
| Recovery | Restoring systems and data, validating security controls, resuming operations. |
| Review | Analyzing the incident, identifying lessons learned, updating plans. |
Ensuring Resilience and Continuous Improvement
Even with the best defenses, incidents can still happen. The goal isn’t just to stop attacks, but to be able to bounce back quickly and learn from what happened. This means having solid plans in place for when things go wrong and making sure we get better over time.
Business Continuity and Disaster Recovery Planning
When a major security event hits, like a ransomware attack or a significant data breach, the business needs to keep running. That’s where business continuity and disaster recovery planning come in. It’s about figuring out what systems are most important and how to get them back online fast, even if the main infrastructure is down. This involves having backups that are stored separately and can’t be messed with, and testing these recovery plans regularly. Without them, recovering from something like ransomware is a lot harder.
- Identify critical business functions: What absolutely has to keep working?
- Develop recovery strategies: How will we restore essential services?
- Test plans regularly: Make sure the recovery process actually works.
- Document everything: Clear steps are vital when under pressure.
Post-Incident Review and Lessons Learned
After an incident is handled, the work isn’t over. A thorough review is needed to understand exactly what happened, why it happened, and how the response went. This isn’t about pointing fingers; it’s about learning. Did our detection systems work? Was our response quick enough? Were there any gaps in our defenses that the attackers exploited? Documenting these lessons and actually using them to improve our security posture is key. It’s how we stop the same mistakes from happening again.
The real value of an incident isn’t just in the immediate fix, but in the knowledge gained for future prevention and response.
Cybersecurity as a Continuous Process
Think of cybersecurity not as a project with an end date, but as an ongoing effort. The threat landscape is always changing, new technologies pop up, and business needs evolve. What was secure yesterday might not be secure tomorrow. This means we need to constantly watch our systems, update our defenses, train our people, and adapt our strategies. It’s a cycle of planning, implementing, monitoring, and improving. This continuous approach helps us stay ahead of threats and maintain a strong security posture over the long haul. It’s about building a security program that evolves with the risks.
| Area of Focus | Key Activities |
|---|---|
| Monitoring | Adjusting detection rules, adding new data sources |
| Vulnerability Mgmt. | Prioritizing new findings, tracking remediation |
| Incident Response | Updating playbooks, conducting tabletop exercises |
| Training | Refreshing user awareness, technical skills |
| Policy & Governance | Reviewing and updating security policies |
Looking Ahead: Making Attack Surface Monitoring a Habit
So, we’ve talked a lot about keeping an eye on your organization’s attack surface. It’s not really a one-and-done kind of thing, you know? Things change fast – new software, new cloud stuff, people making mistakes. That’s why keeping up with continuous monitoring is so important. It helps you spot those gaps before someone else does. By using the right tools and keeping your defenses tuned, you can get a much better handle on what’s out there and what needs protecting. It’s all about staying ahead of the game, making security a regular part of how you operate, not just something you think about when there’s a problem. This way, you’re building a stronger, more resilient defense for the long haul.
Frequently Asked Questions
What is an attack surface, and why is it important to keep an eye on it all the time?
Think of an attack surface as all the possible ways bad guys can try to get into your computer systems or network. It includes things like your websites, apps, and even employee accounts. It’s super important to watch it constantly because attackers are always looking for weak spots. If you don’t keep watch, they might find an easy way in.
How can I know what’s on my attack surface?
First, you need to know what you have! This means keeping a list of all your computers, phones, software, and cloud services. It’s like making an inventory of your digital stuff. Once you know what you have, you can start figuring out how someone might try to attack it.
What’s a SIEM, and how does it help watch for attacks?
A SIEM, which stands for Security Information and Event Management, is like a super-smart security guard for your computer systems. It collects all the security messages (logs) from different places and looks for suspicious patterns. If it sees something that looks like an attack, it sends an alert so you can check it out.
What are ‘cloud misconfigurations’ and ‘shadow IT’?
Cloud misconfigurations are mistakes made when setting up cloud services, like leaving a door unlocked. Shadow IT is when people in a company use apps or services without permission or knowledge from the IT department. Both can create security holes that attackers love to find.
What does ‘defense in depth’ mean?
Imagine a castle with many layers of defense: a moat, high walls, guards, and strong doors. Defense in depth is similar. It means using many different security tools and methods, so if one fails, others are still there to protect you. It’s about not putting all your security eggs in one basket.
How can I find weaknesses (vulnerabilities) before attackers do?
You can regularly scan your systems for known weaknesses, like checking for bugs in software. This is called vulnerability management. You can also have ‘ethical hackers’ try to break into your systems to find problems, which is called penetration testing. Finding and fixing these issues before bad guys do is key.
What happens if an attack does happen?
If an attack occurs, you need a plan! This is called incident response. It involves steps like figuring out what happened, stopping the attack from spreading, cleaning up the mess, and getting everything back to normal. Having a good plan helps you react quickly and reduce the damage.
Why is cybersecurity called a ‘continuous process’?
Cybersecurity isn’t something you do once and forget. The digital world is always changing, with new technologies and new threats popping up all the time. So, you have to keep watching, updating, and improving your defenses constantly. It’s like staying fit – you have to keep exercising to stay healthy.